
Research Activity 4: Learning Skills and Tasks
'...to perform their tasks safely and efficiently, robots must show the same degree of precisions in their skills as humans do. ...'
|
|
In order to perform their tasks safely and efficiently, the robots must show the same degree of precision in their skills as humans do. To provide robots with sophisticated motor skills for flexible and precise motion has proven to be a very difficult task, requiring important low-level programming (with high cost) for finely tuning the motor parameters and for re-calibration of sensor processing. An alternative is to provide the robot with learning or adaptive capabilities, which can be used for on-line optimisation of predefined motor control parameters. Particularly challenging is the problem of how to teach a robot new motor skills, without going through reprogramming, but simply through demonstration. This allows the robot to be programmed and interacted with, merely by human demonstration, a much more natural and simple means of human-machine interface; and it makes the robot flexible with respect to the tasks it can be taught and, thus, facilitates the end-use of robotic systems. This activity addresses the problem of how to teach a robot new motor skills and complex tasks through human demonstration. The learning algorithms to be developed in this activity will be general and address fundamental questions of imitation learning, applied to manipulation tasks. The related areas of research are:
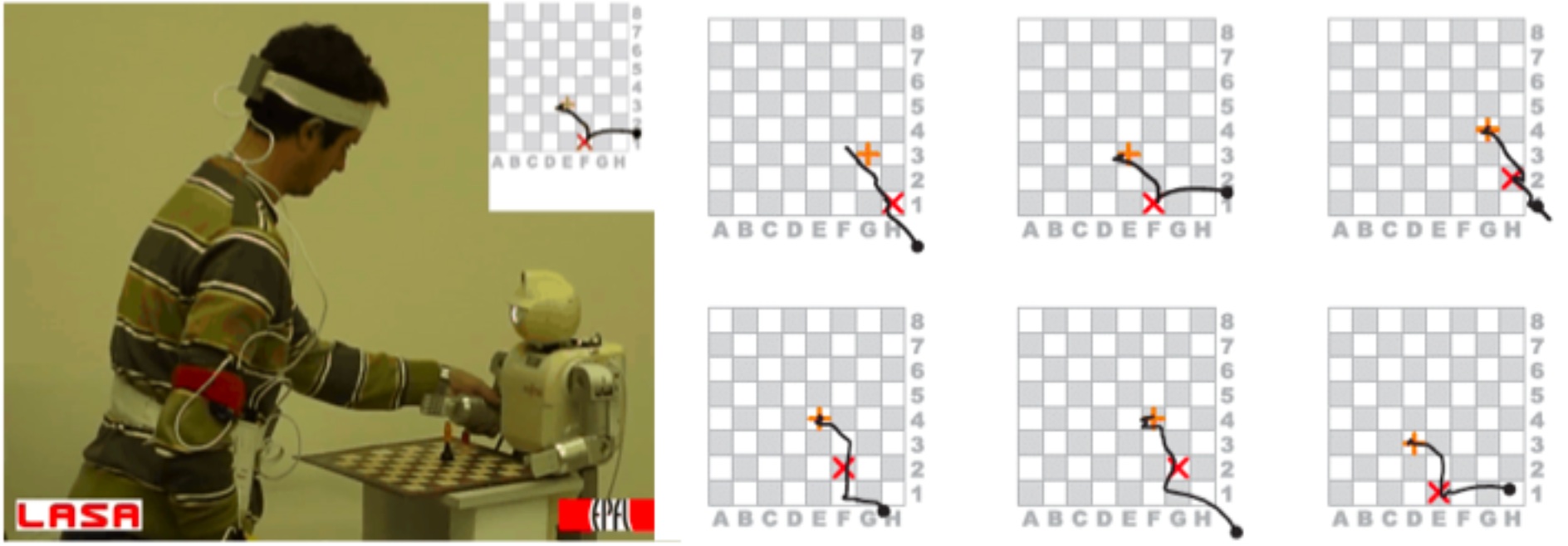
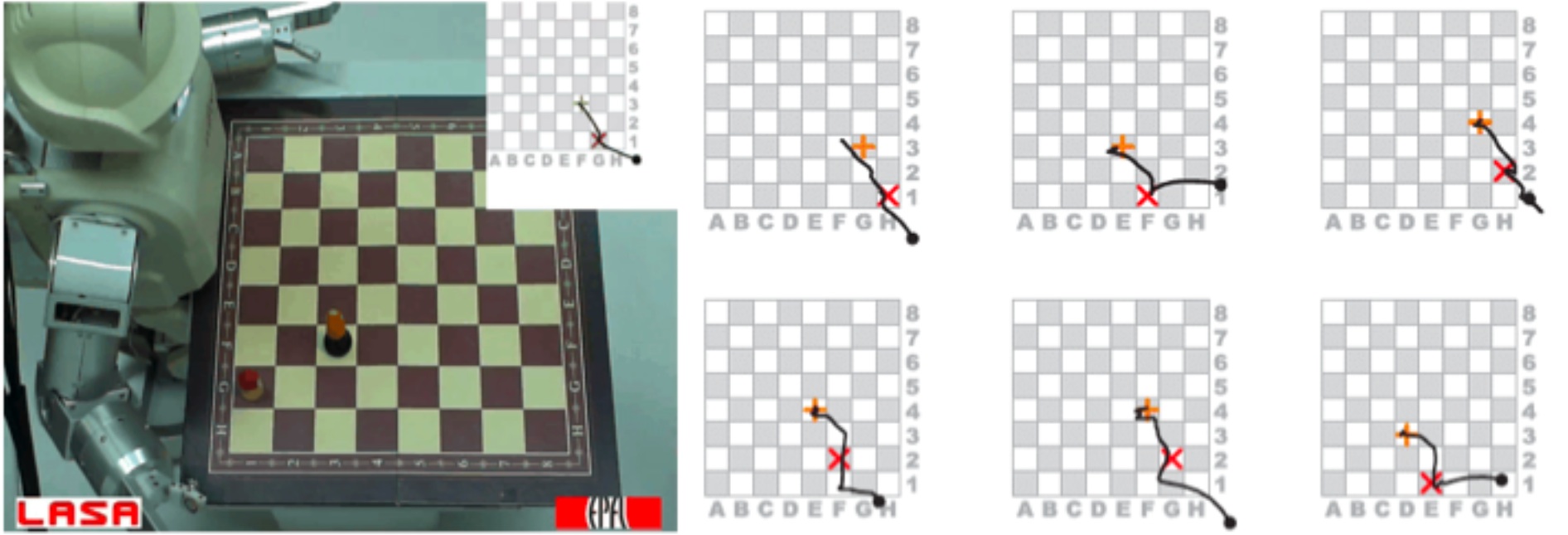
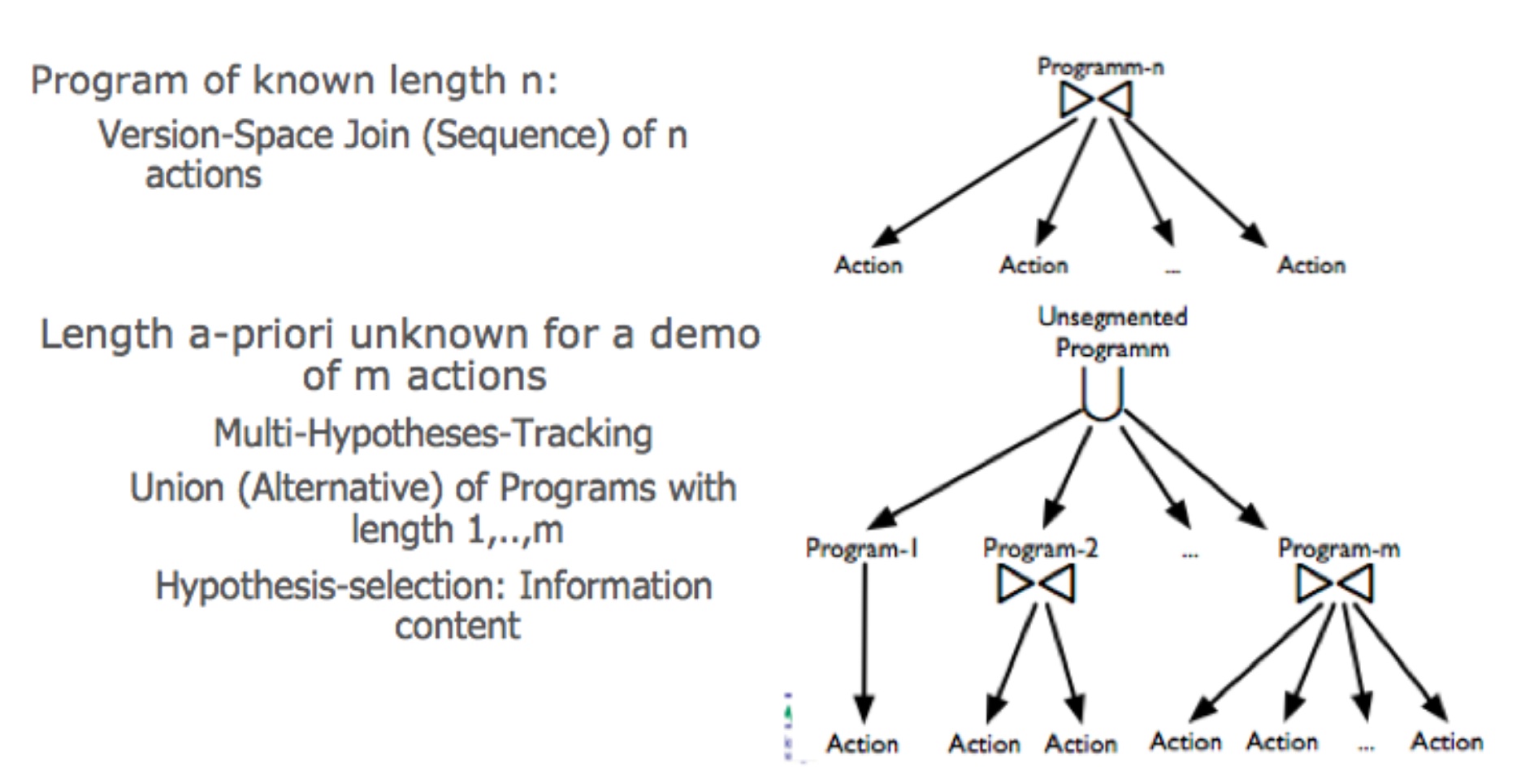
Work conducted in RA4 is related to Key Experiment 3 ('Learning Skills and Tasks') but also related to the other Research Activities. WP4.1 Infering the goals, representation and metric of the task Successful decomposition of the task into uncorrelated constraints and extraction of the goals: An architecture, based on Gaussian Mixture Models, for extracting continuous constraints in time and space [Hersch, 2007 and Calinon, 2007a] has been developed. Moreover, two extensions of this algorithm have been considered. First, we have investigated an on-line version of the extraction of the constraints, based on an incremental version of the expectation-maximization algorithm for learning the Gaussian Mixture Model. This allowed incremental teaching of skills. This was deemed important to allow refining of the skills in an interactive manner. Teaching proceeds as follows: The robot demonstrates its understanding of the task by reproducing the demonstrated gesture. If the robot is unsuccessful, the teacher can then teach the robot again by showing the whole demonstration or only part of it again. We also compared the use of motion sensors versus kinesthetic teaching to teach the robot [Calinon, 2007b and Calinon, 2007c]. Second, we considered the importance of allowing a second form of learning, independent of the human teacher, to complement imitation learning. For this, we investigated the use of reinforcement learning (RL) to allow the robot to relearn a task when the context had changed importantly compared to the context used during the demonstration. To avoid falling in the pitfall of RL of long stochastic searches across the whole motor space of the robot, we used the demonstration to initialize and bound the search. The width of the gaussian mixture was used as a marker of the uncertainty associated at each point of the path. The more uncertainty, the wider could the search around that point be. This was used to enable the robot to relearn a simple reaching task in the presence of obstacles. A complete description of this work is reported in [Guenter, 2007]. Incremental teaching of skills WP4.2 Social context of Robot Social Learning Experiments for scaffolded robot imitation learning and self-adaptation of learning strategies in a social context. Learning Strategies in Social Context: Building on the experimental results from scaffolding studies in 2006, a more detailed combined reanalysis of two separate studies was carried out. The first considered scaffolding breakdowns when humans teach robots. Originally reported in [Saunders, 2006] the experiment reported on how crucial steps in a simple robot teaching process are omitted by human trainers. The results of this study were compared and contrasted with a similar effects from human-robot interaction experiments carried out in the University of Hertfordshire Robot House (results of this combined work was published in [Saunders et al., 2007b]). In that study humans attempted to teach a robot a 'setting the table' task with responses of the robot being controlled by a human 'Wizard-of-Oz' operator. Results confirmed the paucity of explanation given by many of the participants and emphasized the benefits in researching ways to model robot feedback appropriately in order to direct, encourage and confirm the human teaching steps (one way of providing a mechanism for robot responses in this manner was outlined in [Saunders et al., 2007a] as a direct result of studies carried out in 2006). The second study considered how the adaptation of scaffolded teaching strategies could be beneficial both for a robot learner in terms of processing efficiency and for a human trainer in terms of reduced training complexity and training steps. These studies were reported originally in [Saunders, 2006] and reanalysed in conjunction with a more complex HRI study where the human teachers spontaneous levels of event segmentation when analysing their own explanations of a routine home task to a robot. The results suggested the existence of some individual differences regarding the level of granularity spontaneously considered for the task segmentation and for those moments in the interaction which are viewed as most important. This work has been accepted as a journal paper (see [Otero et al., 2007]). The ROSSUM architecture for Humanoid Platform: The ROSSUM teaching and scaffolding system architecture for Humanoid has been developed. Hardware, networking and software integration of the ROSSUM architecture support a switch from a discrete set of movement primitives (on the previous mobile robot platform) to a dynamic set of activities (on the humanoid platform. The key activities included hardware design and implementation of the humanoid robot to include non-powered proprioception running independently from actuators. This extension allows the human trainer to physically manipulate the robot using the self-imitation methods described in [Saunders, 2006] (whereas in the mobile robot experiments the effects were simulated though a teleoperation interface). From the sensory side the VooDoo body tracking system (developed by Cogniron partner UniKarl (Cogniron function CF/ACT) was successfully integrated into the platform. The design also exploits network protocols using the YARP infrastructure which will allow easier future integration and development. Experiments on Human Scaffolding Modifications when carrying out a Task: A joint experiment was carried out in 4th quarter 2007 between the University of Hertfordshire (UH) and University of Karlsruhe (UniKarl). The aim of the experiment was to study whether minor constraints/ modifications of human scaffolded actions when carrying out a task could be positively beneficial in terms of robot technical recognition of those actions and secondly whether these action constraints/modifications would be both acceptable and would not be overly onerous to the human. Work carried out at UH WP4.3 Incremental Knowledge Acquisition of Complex Tasks Report on building of and reasoning over complex task knowledge. Introduction: A comfortable way to provide a robot companion with knowledge about how to perform common household tasks is for a human user to demonstrate and teach tasks to the robot in a natural way. In WP4.3, algorithmic methods and an actual system have been developed, enabling a service robot to learn complex household manipulation tasks from few demonstrations and improve the task knowledge with further demonstrations. The main concept centers around a knowledge acquisition system, capable of observing natural human demonstrations of household tasks. The observed tasks are segmented and interpreted, leading to an abstract, symbolic hierarchical-functional task representation, so-called macro- operators. They form tree-like abstractions of a task that both include a decomposition of a task into modular subtasks and a relational model of the preconditions and effects of the task. The task is recursively decomposed down to an elementary-operator level that comprises the robot-specific sensory- motor couplings on a certain robot type. The general concept is described in [Pardowitz, 2007a]. The latest work in WP4.3 focusses around algorithmic methods to organize task knowledge in taxonomies of similar and conceptually related tasks to improve reusability of acquired knowledge for incremental learning. This approach also reduces the number of necessary demonstrations. Incremental learning of task precedence graphs: Learning abstract patterns of order in certain classes of tasks is described in [Pardowitz, 2007b]. Given a single task, there are possibly different ways to achieve the effects of this task. These can be different orders of the actions constituting the task. The task itself may possess some degrees of freedom in order while being constrained in the ordering of other actions. An example is laying the table with a plate, a saucer and a cup: As the cup should be placed on the saucer, the saucer must be on its final position before the cup can be placed on it. On the other hand, the outcome of a task execution does not depend on whether the plate is placed before, between or after the other two objects have been placed. Therefore, some actions of the tasks sequentially depend on others while others are independent. While the learning system can not decide after seeing only a single example, it seems a viable approach to supply it with more sample demonstrations, applying different task execution orders. In order to learn task knowledge from even a single demonstration sufficient for execution but improving the learned task when more knowledge in form of task demonstrations is available, an incremental approach is chosen. This incremental learning mechanism for task precedence graphs allows a correct precedence graph to be learned from even a single example while still maintaining the ability to incorporate new knowledge in order to refine the task knowledge. Version space algebra for learning of repetitive task patterns: Representing repetitive task patterns in an abstract, formal manner is described in [Pardowitz, 2007c]. Since programs that involve repetition are usually complex entities and can not easily be represented by atomar expressions, the concept of Version Space Algebras (VSA) is introduced. This allows to represent hypotheses on programs and underlying loop structures in a hierarchical manner. They are constructed out of atomar or other compound hypotheses, resembling the tree-like structure of the syntax-tree of a program. The Version Space Algebra (VSA) as used for programming by demonstration is able to track multiple hypotheses on programs simultaneously. In order to allow the hypotheses to be compared with others in terms of adequacy, an evaluation function was defined and implemented that assigns a probability to each hypothesis in the version space. This allows to choose the best hypotheses before the version spaces have collapsed towards a single hypotheses and to introduce background knowledge into the hypotheses evaluation. This version space algebra can be applied applied to the problem of learning loop structures for everyday houshold tasks. version space design - program
2004 - D4.1.1 Evaluation of subgoals extraction algorithm on kinematics data of human motion and on objects displacement RA4 presentation(by Aude Billard (EPFL)) Below are only listed some of the RA-related publications, please see the Publications page for more.
|

 DishwasherBasket.avi
DishwasherBasket.avi
![]()
![]()
![]()
An Integrated Project funded by the European Commission's Sixth Framework Programme