 Partners involved Partners involved
Objectives
Results
Final review presentation
Videos
Deliverables
|
 Partners involved(RA leader) Partners involved(RA leader)
 UniBi,KTH, UH and LAAS UniBi,KTH, UH and LAAS
Objectives
Spoken language is generally considered the most natural means of communication for humans. However, in real-life situations, speech will always be augmented by other modalities, such as gesture, mimic or gaze. Moreover, communication frequently incorporates visual or haptic information about the current situation. Single modality dialogue restricted to speech only can be considered as an artificial way of communication induced by telecommunication technologies. This might be appropriate for human-computer interaction as long as the communication partners do not need to refer to a common environment. In embodied communication, however, both communication partners act in and are able to manipulate a shared situational context. As a consequence the reference to a common environment plays an important role in the communication, which therefore will be multi-modal.
A robot companion is designed to operate in an environment populated by humans. It interacts with persons in their vicinity. Its communication capabilities must match those of its human peers as closely as possible. Therefore the robot must have the ability to engage in a multi-modal dialogue integrating speech and gestures, as well as visual and haptic information.
In that context, the goal of this research activity will be to develop conceptual models, investigate algorithmic solutions and implement and evaluate prototypical systems exhibiting the fundamental capabilities of multi-modal dialogue.
Work conducted in RA1 is related to Key Experiment 1 (The Robot Home Tour) but also related to the other Research Activities.
Results
WP1.1 Adaptive multi-modal dialog
The main focus of WP1.1 was the design and the implementation of adaptive dialogue
strategies based on an appropriate user model. The goal of this effort is to increase usability
and acceptability of the system to different types of users.
Our approach follows the well established general adaptation schema proposed
by Jameson. The central construct in this schema is the user model that specifies characteristics,
needs, preferences and goals of users that are typical for an application. The content of the user model
is often defined in terms variables, the values of which differ between users.
The major innovation of our approach is the broad coverage of the user model and the system's ability to vary its initiative behaviors.
The main components of the adaptation scheme are summarised in the following.
- User model
The user model specifies characteristics of users concerning their interaction expe-
rience and preference. In our current implementation, each user is modeled by three variables:
experience level (and interaction frequency), help-seeking type and interaction type, which ad
dress the issue of task success, interaction control and interaction pleasure, respectively.
- Information collection
The following information from the user is collected: (1) the inter-
action frequency of a given user (for user experience level and user interaction frequency); (2)
whether the user follows system's task-related initiatives, that is, whether she reacts positively
to help given by the system (for help-seeking type); (3) whether the user uses phrases that are
typical for human-human interactions, e.g., "Thank you", "Sorry", "How are you?" (for inter-
action type).
- User model acquisition
Once a user is identified at the beginning of the interaction, her values
for experience level and interaction frequency are increased.
- User model Application
During an interaction, the dialog system interpretes interaction situ-
ations depending on the values of the user model. Some of the interaction situations
require an online evaluation of the user's and the system's performance. An indicator for per-
formance problems of the user are the number of illegally proposed tasks. Indicators for robot
performance problems are perception problems such as speech and gesture recognition errors.
- Prediction or decision about the user
The behavior variations of the system concern the con-
tent and the frequency of the system's initiatives. Four attributes are specified for each initiative:
Type (task-related or social initiatives), Group (min, max, or med, indicating the frequency of
initiative that should be used for the current user), Trigger (the interaction situation, in which
the system has to make a decision about taking the initiative) and Priority (priority of this initia-
tive, relevant in case of multiple possible initiatives). Given a trigger and the current user profile
(based on the values of the user model), the system makes a decision on whether to take an ini-
tiative of either type and/or what initiative to take.
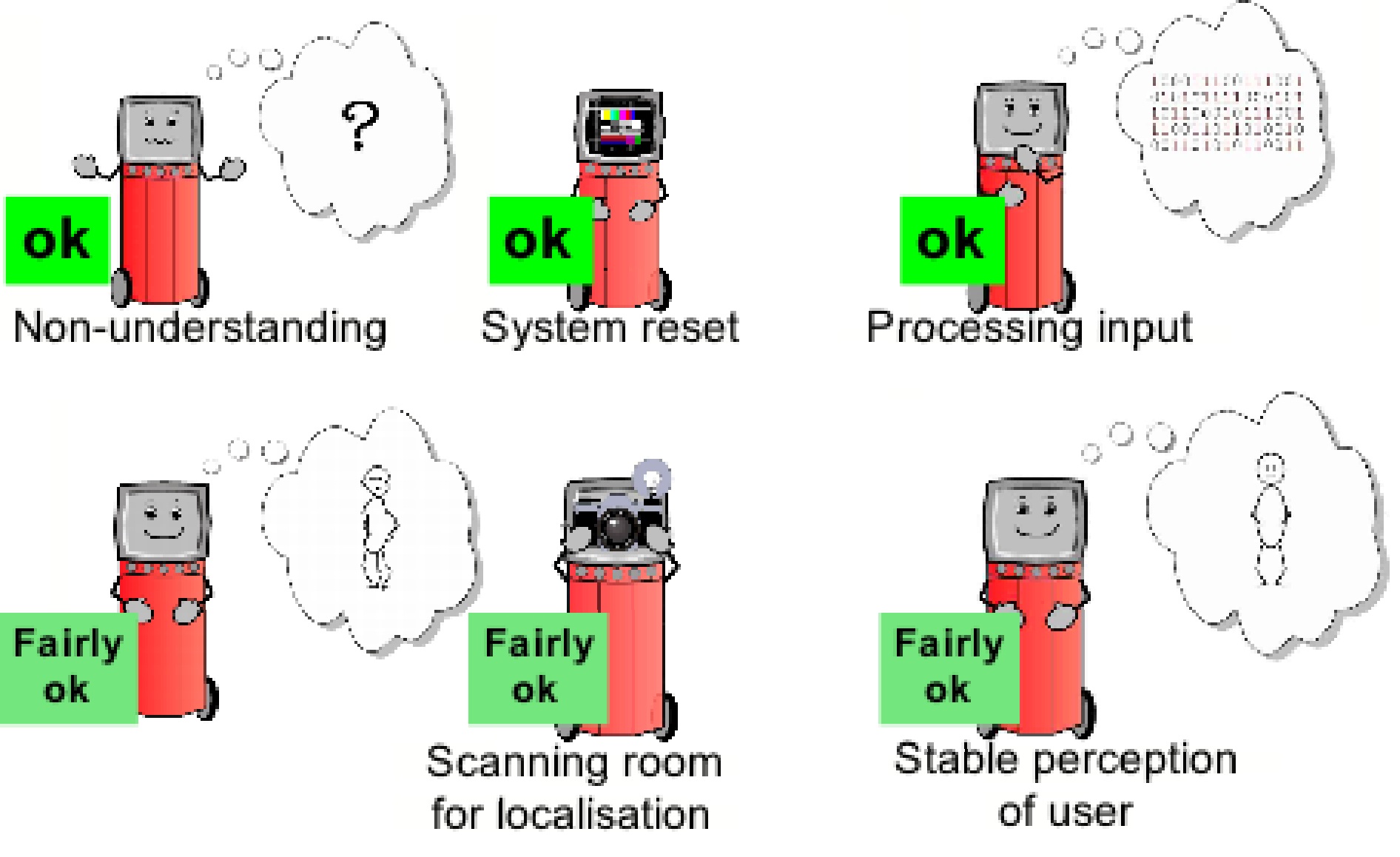
The figure shows the different concepts assigned to the various Mindi display
Our adaptation approach is a powerful mechanism and its benefits include the following three points.
Firstly, the three variables of the user model address both aspects of usefulness and social ability of a
robot companion and enable them to be operationalized
with clearly defined system behaviors. Secondly, the parameters of initiative frequency softens the
adaptation behavior of the system and reduces user confusion caused by variable system behavior
(which is a common problem for adaptive systems). Thirdly, the system can be implemented in a way
that the major behavior control is sourced out to configuration files so that modifications can be easily
carried out.
Observations from evaluation:
Evaluation mainly focused on the adaptation of the speech input control which turned out to be very
successful as compared to the previous approach. While without an adaptation scheme only 63%
(74% after user instruction via a demo-video) of the user utterances were processed by the system,
the adaptive input control increased the overall processing rate to 96% while the false positive rate did
not increase significantly.
Further noteworthy results concern the adaptation of the system's task-level initiative. Although the
adaptation scheme foresees different levels of information provided to the user depending on the user's
type, it turned out that regardless of the user type, the robot has to provide much more specific infor-
mation in many situations. We therefore designed and implemented a much more explicit grounding
strategy. For example, the verbal feedback concerning the instruction for the user after a (system or
user initiated) system reset now specifies the time the user should wait before s/he continues the inter-
action ('Wait 5 seconds after the reset and then say hallo again'). This change was added due to the
fact that users would wait for several minutes for a signal from the robot after the reset, apparently
expecting a complete system re-boot.
Also, the virtual robot character 'Mindi' which provides non-verbal feedback has become more active
in order to display internal system state information in more detail. The virtual robot character Mindi displays relevant system states (such as 'following',
'processing', 'having technical problems', 'not understanding', 'having performance problems' and
'being surprised') as well as important perceptual states (such as 'seeing no person', 'seeing one
person', 'seeing two persons' etc.).
Lessons Learned:
In general it can be stated that in more task-oriented interaction sequences the system feedback needs
to be more specific regardless of the user type. However, analyses of the users' reactions to the sys-
tem's feedback indicate that there are situations where the goal of maintaining mutual understanding
is neglected in favor of keeping the communicative flow up. Such situations arise when the interaction
is more socially-driven, for example during the greeting or good-bye phases. In these phases, users
do not care whether or not the system does understand or reacts in an unexpected way. If this happens
users will simply proceed with the interaction.
Thus, the expectations of the user play an important role in the interaction and in the acceptance of
the system's feedback and will therefore be a necessary focus of future research.
WP1.2 Representation and integration of knowledge for an embodied multi-modal dialogue system
Handling of multiple-users situations
We implemented a mechanism for the system to be able to correctly make the decision whether to
process speech input forwarded by the speech recognizer, which is important for the robot to achieve
situation awareness. The dialog system draws on three different parameters to make this
decision: the content of the speech input, the input from the person detection module and the dialog
expectation. The graded decision making process of this approach has the advantage that
different levels of restrictions can be adopted in different situations.
Integration of planning with dialog modeling
The objectives was (1) to
investigate integration of a dialog component with a planning module and to realize the link between the robot supervision system (Shary) and the
high-level HATP planning system, to implement a dedicated communication scheme that supports
robot task achievement in a human context and (2) finally to integrate these features in the KE2
experiment.
We have considered three challenges: (A) Starting and ending the inter-
action, (B) robot-initiated plan-modification, and (C) user-initiated plan-modification.
These challenges have been addressed in the following way. Note that complementary information
concerning integration can be found in the RA6 and RA7 deliverables.

Snapshot during communicating spatial hierarchy scenario
Integration of dynamic topic tracking with dialog modeling
In order to demonstrate situation awareness with respect to the semantics of the user's utterances we
integrated an approach to dynamically track topics in situated human-robot interactions. By dynami-
cally we mean that neither the topics nor the amount of topics are predefined but adjusted dynamically
during the interaction. This enables the system to draw simple inferences without explicit reasoning
and without a pre-defined knowledge-base by associating words and objects that 'belong', that is
co-occur together.
The topic tracker has been integrated with the dialogue module and has been evaluated offline (pre-
cision and recall of topic classification) and online. It was shown that subjects were sensitive to the
robot's ability to detect connections in the discourse.
Integration of localisation with dialog modeling
This concerns our work on spatial representation by integrating the localisation approach
from KTH with the dialogue. Based on experiences from user studies in RA1 and RA3 a mapping
hierarchy was defined where spatial points are represented as either rooms, areas or objects, depending
on how users refer to them and what role they play in further interactions. Our hypothesis is that it
will be easier for users to interact with a robot when they have similar representations of the spatial
environment.
Further publications within this WP in the third phase concern results from work accomplished mainly
in the second phase of the project.
WP1.3 Evaluation methods
The evaluation activities that are related to RA1 started by the Wizard-of-Oz study performed in
2004. This was an evaluation of an integrated system with the aim of putting users into a
context that can be characterized as "future use", i.e., the users were interacting with something
that we aimed to build in the years to come. The result of the analyses informed the design of the
system development. Subsequent evaluation activities have been targeting specific dialogue design
issues. In the last phase we evaluated and refined the design of the BIRON robot which is used
to instantiate the Home Tour scenario (KE1) during three use session, and analyses, followed by a
refinement of the system. We have also used a video-based approach to measure attitudes towards
different communicative robot behavior.

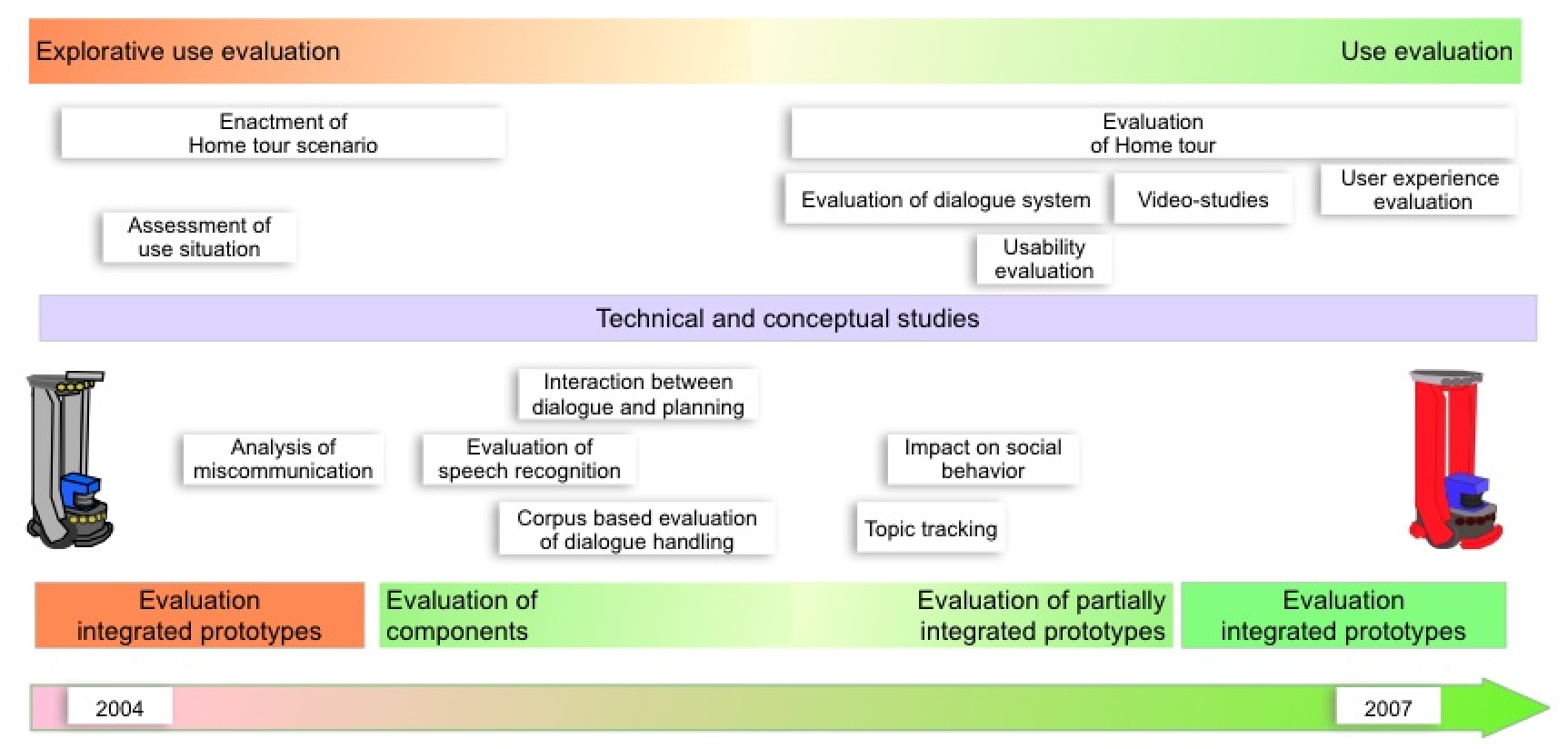
Evaluation activities in RA1. Figure are based on evaluation activities during the project
Lessons learned: Interaction
- Users expect natural language to be used consistently
Users expect the system to appear human-like when it uses natural language to provide information.
There was one issue that illustrates this more than anything. According to the dialogue model of the
system, which was based on a grounding and implemented using a finite-state approach, the user
was supposed to say "stop" to end the ongoing activity. The situations that occurred as a consequence
of this dialogue design appeared slightly peculiar or inconsistent to most users. This means that even
if the system acts corresponding to it's algorithm, and even if the human adapt to the model, the
interaction appear illogical.
The effort of adding transparency by mapping dialogues closely to the inner workings and states of
the dialogue system requires that what becomes visible to the user also makes sense.
- Users' assumptions about human-like qualities
We have learned that there are some things that users seem to have a hard to understand or accept. In
the evaluation of the Home Tour scenarios we have a robot that has a linguistic expressivity that is at
the same level of advancement as a human.
Even if we are not comparing the robot with humans per se human-like qualities may raise expecta-
tions or trigger models of understanding that might cause unforseen use behaviors. This means that
we cannot se a robot only as a machine equipped with some verbal components e.g., speech recog-
nition and speech synthesis. When we trigger the affordances, or mental model, of something that
is capable of using natural language we need to consider what this entails when some aspect that we
usually find in people is not present.
Even if users appear to understand the robot as being a robot with limited perceptual capability, they
have a very vague idea of how the technology works, but more importantly, they seem to assume that
perceptual capabilities for a robot works in a similar manner as for a human.
Lessons learned: methodological considerations
- Testing the right thing
When designing a system that incorporate real and wizard-simulated components we need to take care
that we do not add functionality that overshadows the properties of the system we are about to test.
In other words, we need to establish that the contribution to the behavior of the robot from a specific
component is tested rather than some other component that we are not interested in.
- Evaluation of subconscious design elements
A design that aims to activate, or provides cues for, perceptual processes of users are not aware of at
a conscious level provides a challenge when it comes to evaluation methodologies. It is hard to use
qualitative methods, such as questionnaires and interviews to assess the attitudes towards components
that are not not in focus for the user during the use session. Especially when we do not want to
influence the users so that they become self conscious and act upon their own communicate behavior.
- Expectation management
Another theme with a similar effect was the adding of the ad-hoc capability of recognizing and uttering
the name of the user in the initial greeting phase of the KE1 evaluation. We have established in the
interviews that the users seemed to appreciate this feature of the system.
There seems different ways of understanding this positive feedback. We can interpret this as a positive
evaluation of a "future feature" of the system. We then bring this in to the implication for the next
step in the design.
This feature might cause raised expectation and an overly optimistic picture of what the particular
system that is being evaluated is capable of.
- Providing appropriate boundaries on interaction
It is very important to provide sufficient instruction to allow the user to become involved in the sce-
nario. There also has to be sufficient room for user initiative and improvisations. In practice this
means to include support for providing boundaries for the user. Ideally when boundaries are in place,
the user can act within the scenario without arriving at a state in the interaction where it is unclear
what the possible actions are.
Deliverables
2004 - RA1.1.1 Report on the declarative dialogue model and strategy
2004 - RA1.2.1 Report on the formalism of the modality integration scheme
2004 - RA1.3.1 Report on the evaluation methodology of multi-modal dialogue
2005 - RA1: Multi-modal dialogs
2006 - RA1: Multi-modal dialogs
2007 - RA1: Multi-modal dialogs
Final review presentation
RA1 presentation(by Britta Wrede)
associated videos:



Videos

The beginning of this video shows the first user study, carried out as a Woz study in RA1 at KTH, with a simulation of the state-based dialog in the first year of the project. The second part of the video shows the current state of the dialog system within the KE1 scenario (Home Tour). It shows that by integrating more functionalities (e.g. spatial mapping and localization) and using a real system instead of a simulated one much more interaction management is necessary. This is due to the fact that many technical issues could not be foreseen in the initial Woz study, such as the turning-around of the robot for scanning the room, or getting stuck in the doorframe (not shown here).
References
 Anthony Jameson. Human-Computer Interaction Handbook, chapter Adaptive Interfaces and
Agents. Erlbaum, Mahwah, NJ, 2003. Anthony Jameson. Human-Computer Interaction Handbook, chapter Adaptive Interfaces and
Agents. Erlbaum, Mahwah, NJ, 2003.
Related publications
Below are only listed some of the RA1-related publications, please see the Publications page for more.
- A study of interaction between dialog and decision for human-robot collaborative task achievement, Aurelie Clodic, Rachid Alami, Vincent Montreuil, Shuyin Li, Britta Wrede, Agnes Swadzba. RO-MAN 2007, Jeju Island, Korea
- The Need for a Model of Contact and Perception to Support Natural Interactivity in Human-Robot Communication, Anders Green. RO-MAN 2007, JeJu Island, Korea
- Characterising Dimensions of Use for Designing Adaptive Dialogues for Human-Robot Communication, Anders Green. RO-MAN 2007, JeJu Island, Korea
- Multi-Modal Interaction Management for a Robot Companion Shuyin Li. PhD Thesis, Bielefeld University, 2007
- Why and how to model multi-modal interaction for a mobile robot companion Shuyin Li, Britta Wrede. AAAI Spring Symposium 2007 on Interaction Challenges for Intelligent Assistants (best paper award)
- Evaluating extrovert and introvert behaviour of a domestic robot - a video study Manja Lohse, Marc Hanheide, Britta Wrede, Michael L. Walters, Kheng Lee Koay, Dag Sverre Syrdal, Anders Green, Helge Huttenrauch, Kerstin Dautenhahn, Gerhard Sagerer, and Kerstin Severinson-Eklundh. RO-MAN 2008
- Try Something Else. When Users Change Their Discursive Behavior in Human-Robot Interaction Manja Lohse, Katharina Rohlfing, Britta Wrede, Gerhard Sagerer. ICRA 2008
- Interaction Awareness for Joint Environment Exploration Thorsten P. Spexard, Shuyin Li, Britta Wrede, Marc Hanheide, Elin A. Topp, Helge Huttenrauch. RO-MAN 2007, JeJu Island, Korea
- Making a Case for Spatial Prompting in Human-Robot Communication A. Green, H. Httenrauch. Workshop at the Fifth international conference on Language Resources and Evaluation, LREC2006, Genova, May 22-27.
- Measuring Up as an Intelligent Robot - On the Use of High-Fidelity Simulations for Human-Robot Interaction Research A. Green, H. Httenrauch, E. A. Topp. PerMIS'06, Performance Metrics for Intelligent Systems, The 2006 Performance Metrics for Intelligent Systems Workshop, Gaithersburg, MD, August 21-23, 2006.
- Developing a Contextualized Multimodal Corpus for Human-Robot Interaction A. Green, H. Httenrauch, E. A. Topp and K. S. Eklundh. Fifth international conference on Language Resources and Evaluation, LREC2006, Genova, May 22-27.
- Robust speech understanding for multi-modal human-robot communication S. Hwel, B. Wrede and G. Sagerer. 15th Int. Symposium on Robot and Human Interactive Communication (RO-MAN) 2006.
- A dialog system for comparative user studies on robot verbal behavior S. Li, B. Wrede and G. Sagerer. 15th Int. Symposium on Robot and Human Interactive Communication (RO-MAN), 2006.
- Position Paper S. Li. 2nd Young Researchers' Roundtable on spoken dialog systems In conjunction with Interspeech, 2006.
- Why and how to model multi-modal interaction for a mobile robot companion S. Li and B. Wrede. AAAI Spring Symposium on Interaction Challenges for Intelligent Assistants, 2007.
- A computational model of multi-modal grounding for human robot interaction S. Li, B. Wrede and G. Sagerer. ACL SIGdial Workshop on discourse and dialog In conjunction with CoLing/ACL, 2006.
- BIRON, whats the topic? - A Multi-Modal Topic Tracker for improved Human-Robot Interaction J. F. Maas, T. Spexard, J. Fritsch, B. Wrede, and G. Sagerer. Proc. IEEE Int. Workshop on Robot and Human Interactive Communication (RO-MAN), 2006.
- BITT: A corpus for topic tracking evaluation on multimodal human-robot-interaction J. F. Maas and B. Wrede. Proc. Int. Conf. on Language and Evaluation (LREC), 2006.
- Towards a multimodal topic tracking system for a mobile robot J. F. Maas, B. Wrede, and G. Sagerer. Proc. Int. Conf. on Spoken Language Processing (Interspeech/ICSLP) 2006.
|
